A solo project, currently in beta
Host your services.
Not your monitoring.
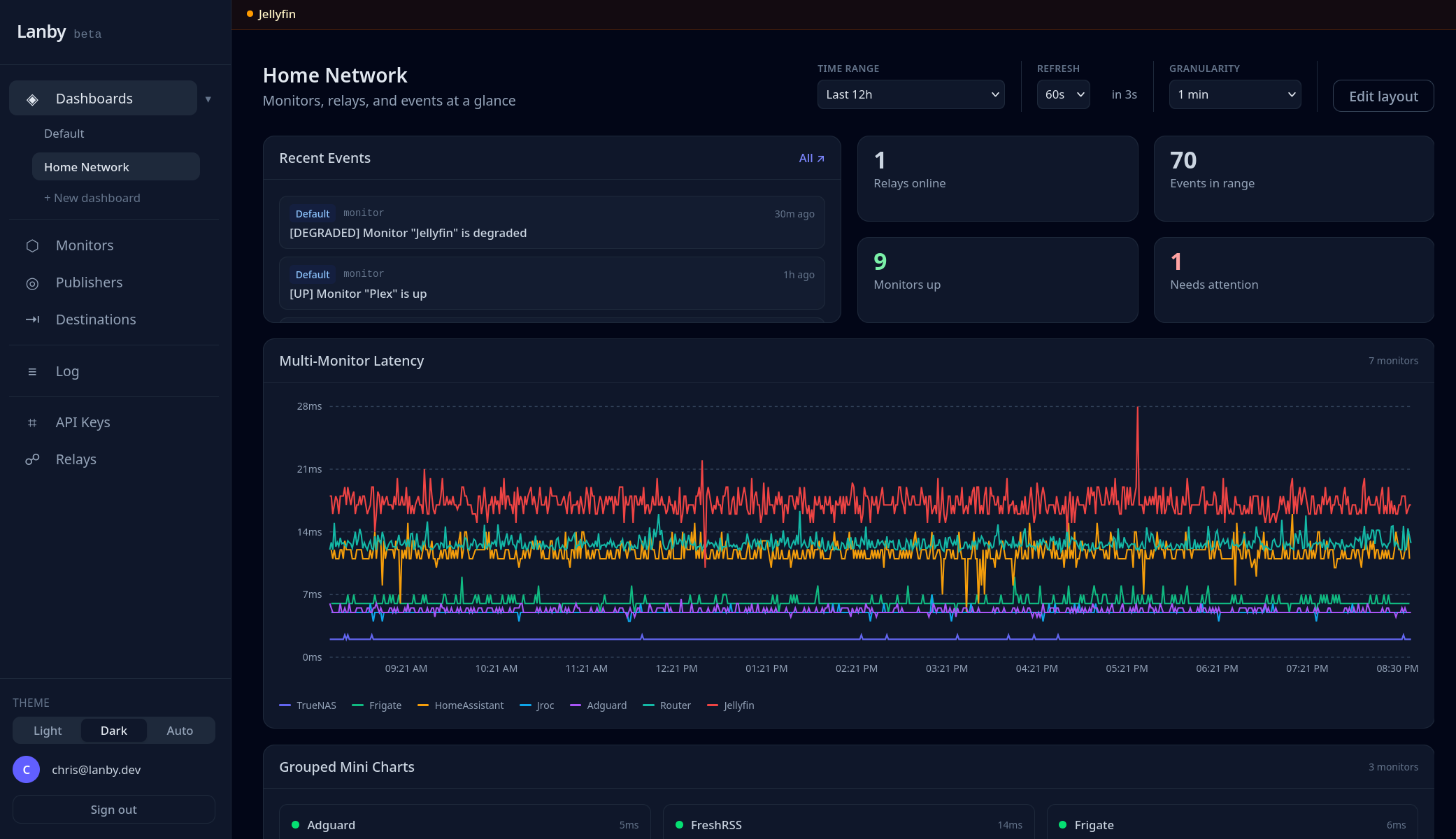
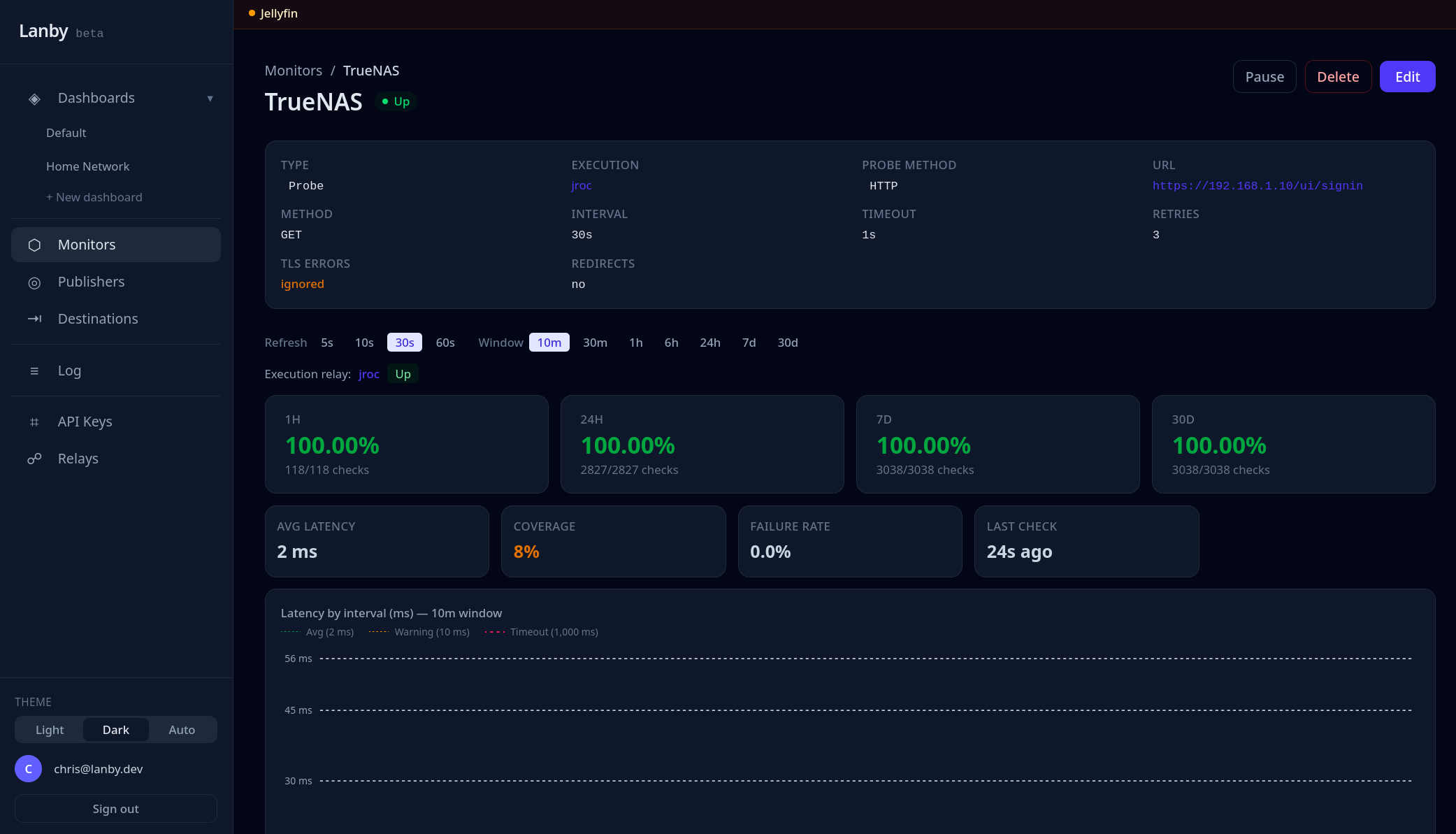
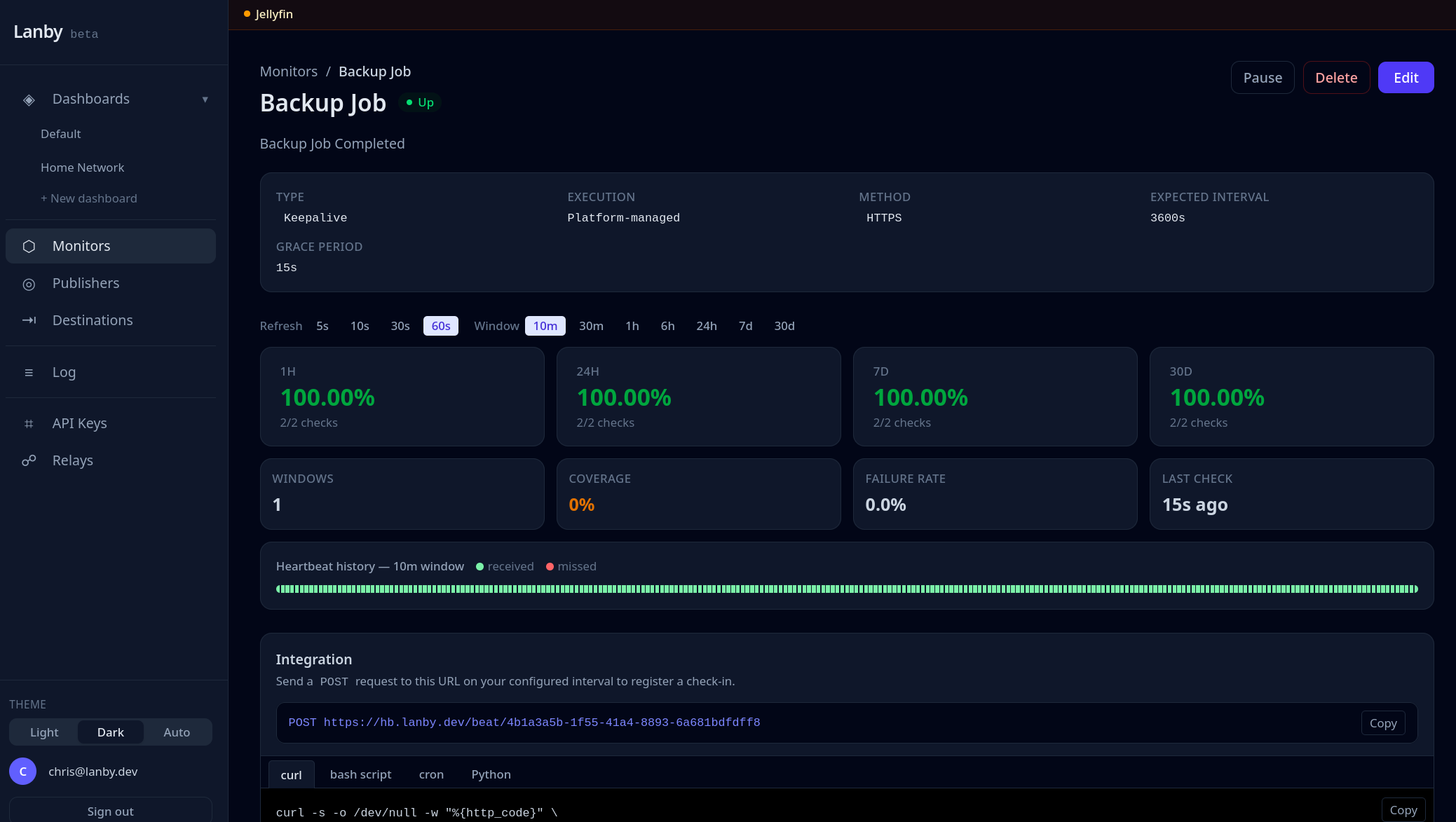
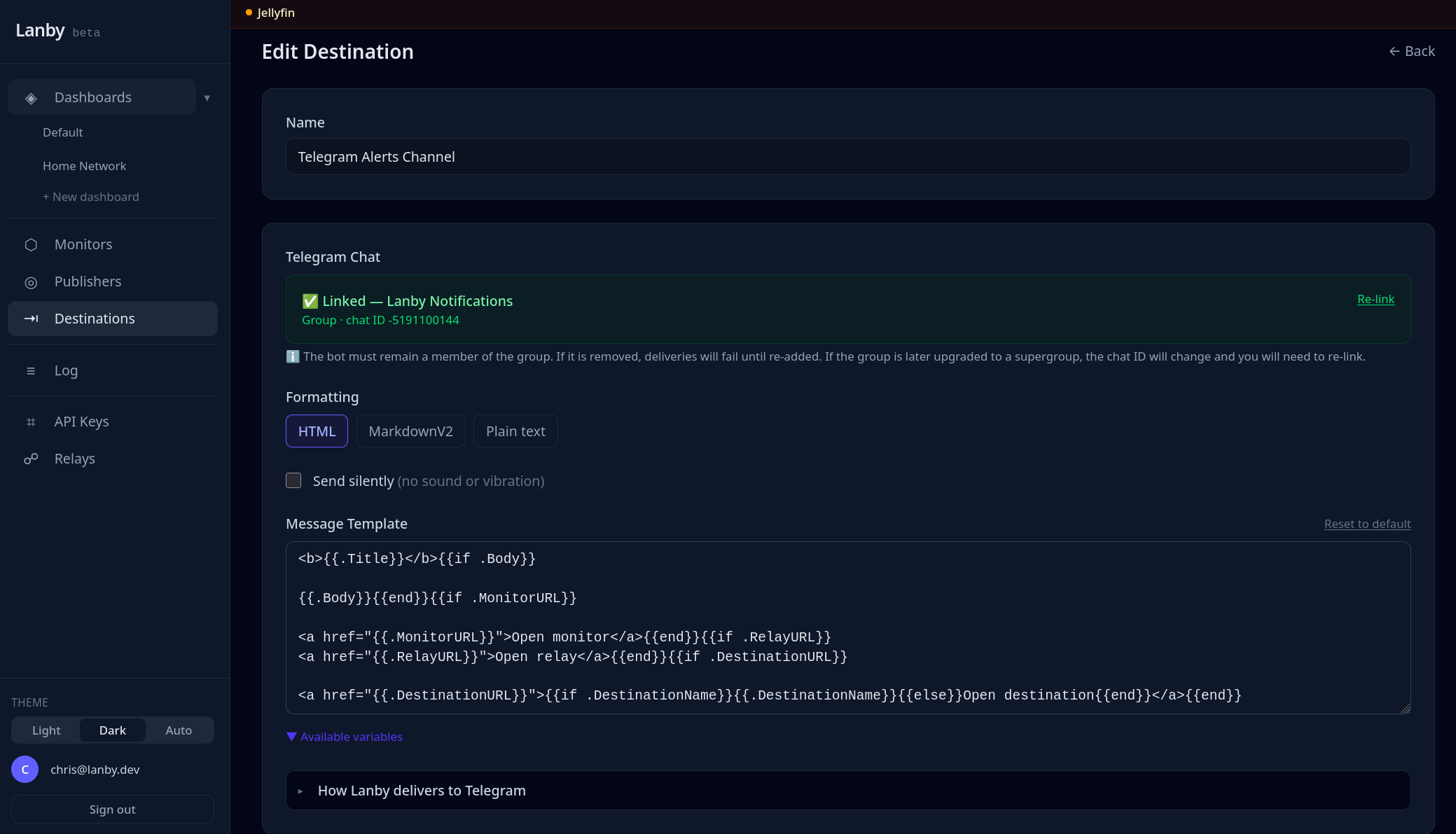
I run a lot of self-hosted services and kept finding out things were broken long after the fact. Tools like Uptime Kuma are great, but now you're hosting your monitoring too — and if that goes down, you're back to square one. Uptime probes, heartbeat alerts, and a relay that reaches everything behind your firewall — no inbound ports needed.
Invite-only for now. Want early access? Join the beta.
3
UP
1
DOWN
1
DEGRADED
142ms
AVG RESP
api.production
probe · api.prod.example.com
UP
worker.01
keepalive · 2m overdue
DEG
ingest.eu
probe · in.eu.example.com
DOWN